




Zarejestruj się do bezpłatnej platformy e-learningowej.
Zarejestruj się bezpłatnieWskazówki, rozmowy, inspiracje
Subskrybuj kanał na YouTube i bądź na bieżąco!


Sprawdź, jak Twoja strona radzi sobie w sieci!
Audytuj bezpłatnieSpis Treści
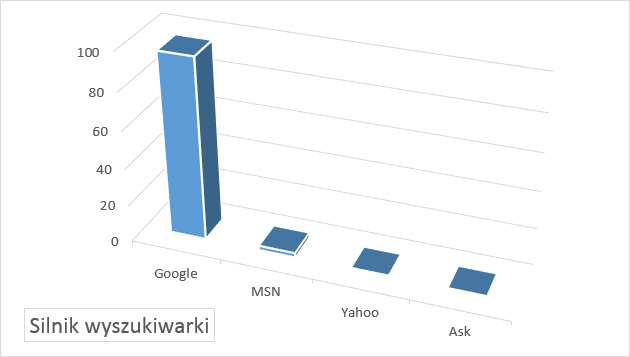
Jednym z kluczowych elementów procesu pozycjonowania domeny jest prawidłowo przeprowadzona optymalizacja serwisu pod kątem wyszukiwarek. Ponieważ różne wyszukiwarki przypisują inną rangę poszczególnym elementom witryny warto skupić się na wyszukiwarkach mających kluczowy udział w rynku, na którym będziemy promować nasz serwis. Jeżeli optymalizujemy polskojęzyczną witrynę mamy ułatwione zadanie, gdyż na chwilę obecną wyszukiwarka Google jest wykorzystywana przez około 97% polskich użytkowników Internetu (dane wg ranking.pl na sierpień 2016).
Optymalizacja strony jest to dostosowanie kodu, treści i grafik pod kątem wyszukiwarek internetowych. Zawsze poprzedza właściwy proces pozycjonowania. Jest niezbędna do skutecznego promowania serwisu w wynikach wyszukiwania – wpływa na eliminację wszelkich błędów w witrynie, powtórzeń treści oraz zminimalizowanie ryzyka otrzymania kary w postaci filtra od wyszukiwarki Google. W przypadku większości popularnych CMS-ów (np. WordPress, Drupal) optymalizację treści można przeprowadzić z ich poziomu. Natomiast optymalizacja kodu wymaga najczęściej ingerencji w kod źródłowy skryptów.
Rozpoczynając optymalizację serwisu, w pierwszej kolejności analizuje się aktualny kod źródłowy strony – przeprowadzona zostaje tzw. analiza techniczna. W jej wyniku zaleca się przebudowę witryny tak, aby była jak najbardziej widoczna dla botów wyszukiwarek i użytkowników. Następnie ma miejsce optymalizacja treści zarówno ze względu na potrzeby informacyjne użytkowników, jak i słowa kluczowe rozpoznawane przez algorytmy wyszukiwarek.

Zakres audytu SEO będzie różnił się w zależności od wielkości i celu strony internetowej. Optymalizacja sklepu internetowego
to proces zdecydowanie bardziej złożony niż przystosowanie do wyszukiwarki kilkustronicowej witryny firmy. Dokument z zaleceniami optymalizacyjnymi będzie obszerny, ale wdrożenie wszystkich zmian pomoże osiągnąć wysokie pozycje w wynikach wyszukiwania, zaistnieć w świadomości internautów oraz zyskać ich przychylność, co ma skutkować większą ilością zamówień w e-sklepie.
Ze względu na stale zmieniające się algorytmy wyszukiwarek optymalizację strony należy wykonywać cyklicznie i regularnie. Śledzenie zmian w wyszukiwarkach i obserwowanie aktualnych trendów sprawia, że strony internetowe są cały czas dobrze zoptymalizowane.
Oczywiście nie znamy algorytmów według których są oceniane nasze witryny przez wyszukiwarki, ale dzięki takim zasobom jak „wskazówki dla webmasterów”, analizie witryn znajdujących się na początku wyników wyszukiwania oraz rzeszy pasjonatów SEO, możemy z dużym prawdopodobieństwem wskazać grupę czynników mających kluczowy wpływ na proces optymalizacji witryny pod kątem wyszukiwarki Google. Należą do nich:
Przed przystąpieniem do optymalizacji witryny, należy dokonać wyboru słów kluczowych. Warto do tego celu wykorzystać popularne narzędzie, jakim jest Google Keyword Planner służący do wyodrębnienia i oceny potencjału słów kluczowych, na jakie w przyszłości będziemy pozycjonować serwis. Odpowiednio dobrane słowa kluczowe to połowa sukcesu. Możemy ich szukać w obrębie naszej witryny, jak i na stronach konkurencji. Przy pomocy takich narzędzi jak Ahrefs, Majestic, czy SemStorm możemy sprawdzić, na jakie słowa kluczowe pozycjonuje się konkurencja i wykorzystać je w obrębie własnego serwisu.
Wyszukiwarki zwracają szczególną uwagę na tytuł i opis strony (znacznik <title> i <description>). Oba elementy wraz z adresem url, są im potrzebne do zaprezentowania danej podstrony w wynikach wyszukiwania. Jeżeli nasza strona nie posiada tych znaczników lub ma je uzupełnione nieprawidłowo, wyszukiwarka może użyć innego tekstu na naszej stronie (lub na stronie, na której znajduje się odnośnik do naszej podstrony) w celu dostosowania wyglądu do „aktualnie obowiązujących standardów” lub usunąć naszą podstronę z wyników wyszukiwania. Jeżeli chcemy, aby nasze strony prezentowały się prawidłowo (przykład poniżej).


Należy zadbać o to, aby:
uzupełnić i zróżnicować tytuły i opisy na wszystkich podstronach w serwisie,
zapewnić odpowiednią długość tytułów oraz opisów,
zapewnić odpowiednie dopasowanie tytułów i opisów do zawartości danej podstrony.
W tym celu zalecamy skorzystać z usługi Google Search Console (dawniej Google Webmasters Tools), gdzie w zakładce Status w wyszukiwarce > Udoskonalenia HTML odnajdziemy informacje, które tytuły i opisy wymagają naszej uwagi.


Powyższe raporty będą dostępne wyłącznie po prawidłowym zweryfikowaniu praw własności do serwisu.
Można też skorzystać z alternatywnych narzędzi, jak Screaming Frog, które mogą przeskanować optymalizowaną witrynę i wskazać duplikaty lub braki znaczników.
Podstawową wartością każdego serwisu jest jego zawartość, czyli tzw. content. Jedną z najczęściej obecnie stosowanych strategii promocji serwisu w sieci jest tzw. „content marketing” (…”jest to strategia polegająca na pozyskiwaniu potencjalnych klientów poprzez publikowanie atrakcyjnych i przydatnych treści, które zainteresują ściśle sprecyzowaną grupę odbiorców.” Źródło: https://pl.wikipedia.org/wiki/Content_marketing). Publikowanie w ramach witryny ciekawych, wiarygodnych i użytecznych treści może być skuteczną strategią na wzbudzenie zainteresowania zarówno ze strony użytkowników, jak i crawlerów Google, które ze względu na swoją specyfikę indeksują strony w trybie tekstowym.
Aby robot Google odwiedzający nasz serwis zainteresował się opublikowaną na naszej stronie zawartością, treść tej strony musi spełniać kilka warunków. Musi być unikalna, wiarygodna, ciekawa, wysokiej jakości i przede wszystkim dostępna. Jeżeli ukrywamy treści na stronie, publikujemy wyłącznie cudze materiały, generujemy treść automatyczną lub treść mającą znamiona spamu, np. przesyconą słowami kluczowymi nie możemy liczyć na wysokie pozycje w wynikach wyszukiwania, gdyż wg wyszukiwarki nie dostarczamy użytkownikom Internetu unikalnej treści zasługującej na ich uwagę.


Poza publikacją treści warto rozwijać także inne formy przekazu mogące nieść za sobą użyteczności dla użytkowników takie jak: grafiki, filmy, programy czy aplikacje… Strony publikujące interesujące i angażujące materiały (bez względu na ich formę) mogą liczyć na „naturalne” zainteresowanie użytkowników, które w dalszej kolejności może przełożyć się na zbudowanie społeczności dzielącej się informacjami (oraz linkami) i owocować wzrostem odwiedzin serwisu.
Najczęściej wykorzystywanym elementem linkowania wewnętrznego na każdej stronie internetowej jest menu. Dobrze zaprojektowane ułatwia poruszanie się po witrynie. Dla robotów indeksujących strony internetowe tekst zawarty pod linkiem w menu może posłużyć do oznaczenia zawartości docelowej podstrony. Prawidłowo zaprojektowane menu może wspomagać proces optymalizacji – szczególnie przy rozbudowanych projektach. Dla takich serwisów zalecane jest stworzenie drzewa kategorii i podkategorii grupujących odpowiednią zawartość (najczęściej zbliżoną tematycznie). A ich zagnieżdżenie nie powinno przekroczyć trzeciego poziomu (strona główna > kategoria > podkategoria > artykuł/produkt). W ten sposób każda podstrona witryny będzie dostępna przy maksymalnie 3 kliknięciach. Takie rozwiązanie jest preferowane zarówno przez użytkowników, jak i roboty indeksujące sieć.
Często spotykanym elementem wspomagającym nawigację w serwisie jest tzw. menu okruszkowe (breadcrumbs, poprawna implementacja powinna opierać się o tzw. mikro formaty, wg następującej specyfikacji https://schema.org/BreadcrumbList). Poza jego oczywistą funkcją, jest też doskonałym nośnikiem informacji dla wyszukiwarki na temat zawartości dostępnej pod linkiem oraz oceny istotności danej podstrony w ramach całej struktury.
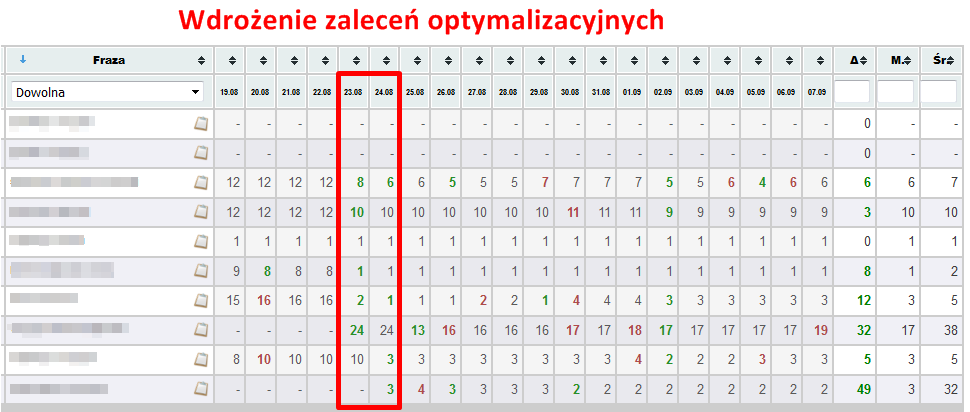
Poprawa linkowania wewnętrznego i wdrożenie zaleceń optymalizacyjnych wpływają na wzrost pozycji w wynikach wyszukiwania.
Jeżeli struktura podstron w serwisie jest daleka od ideału lub uniemożliwia ona robotom dotarcie do wszystkich podstron w witrynie warto przygotować mapę strony w formacie XML (dokładny opis konstrukcji takiej mapy znajduje się na stronie: www.sitemaps.org/protocol.php). Po utworzeniu takiej mapy należy ją dodać do Search Console lub umieścić odpowiednią regułę w pliku robots.txt (szczegóły tutaj: https://support.google.com/webmasters/answer/183668).
Elementem, na który również należy zwrócić uwagę w procesie optymalizacji struktury serwisu są adresy url. Zaleca się, aby do ich konstrukcji stosować wyłącznie małe litery, myślnik do rozdzielania wyrazów i ewentualnie cyfry.
Dokument HTML można potraktować tak samo jak każdy inny dokument tekstowy, w ramach którego publikujemy różnego rodzaju materiały. W celu wyznaczenia jego struktury oraz nadania odpowiedniej hierarchii poszczególnym jego częściom stosujemy nagłówki. Analogicznie w dokumencie HTML zaleca się stosowanie nagłówków od <h1> do <h6> w celu nadania znaczenia i uporządkowania poszczególnych elementów naszej witryny. Stosując nagłówki na stronie internetowej należy pamiętać aby:
nagłówki wyższego rzędu występowały w kodzie strony przed nagłówkami niższego rzędu,
ilość nagłówków była proporcjonalna do ilości treści na stronie i struktury serwisu,
unikać stosowania wielu nagłówków <h1> na podstronie (mimo iż specyfikacja HTML5 dopuszcza stosowanie wielu nagłówków <h1> w ramach pojedynczej podstrony).
Nie ma obowiązku używania wszystkich nagłówków na stronie, dla większości serwisów wystarczą dwa pierwsze (<h1> i <h2>). Istotnym jest, aby zachować ich odpowiednią kolejność i hierarchię w serwisie. Przykładowy, zoptymalizowany dokument HTML mógłby posiadać następującą strukturę nagłówków:


Nagłówek pierwszego stopnia <h1> jest najważniejszym nagłówkiem na stronie i powinien służyć do określenia tematyki publikacji. Nagłówki <h2> i <h3> mogą służyć do rozdzielania śródtytułów, natomiast nagłówki od <h4> do <h6> mogą być wykorzystane do porządkowania pozostałych modułów lub grup treści na stronie. Im wyższego rzędu jest nagłówek tym większe ma on znaczenie dla SEO.
Wyszukiwarki zwracają uwagę nie tylko na to, czy publikujemy unikalne treści w stosunku do innych stron w sieci, ale też na duplikację treści w obrębie naszego serwisu. Zaleca się unikanie powielania większych fragmentów treści na podstronach własnej witryny. Jeżeli, z jakiś względów nie można tego wyeliminować, należy poinformować wyszukiwarki o tym, która zawartość powinna zostać zaindeksowana.
Podstawową kwestią ograniczającą duplikację jest przekierowanie całej domeny na jedną wersję adresów (z przedrostkiem www lub bez). Przekierowania są wymagane, gdyż dla wyszukiwarek adresy z „www” lub „bez www” nie są tymi samymi. Najskuteczniejszym sposobem na wykonanie tego przekierowania jest umieszczenie w pliku .htaccess następującej reguły:
RewriteEngine On
RewriteCond %{HTTP_HOST} ^mojadomena.pl(.*) [NC]
RewriteRule ^(.*)$ http://www.mojadomena.pl/$1 [R=301,L]
Kluczowym elementem jest użycie przekierowania 301. Często popełniamy błędem optymalizacyjnych jest stosowanie przekierowania 302, które jest interpretowane jako przekierowanie tymczasowe.
Po wyeliminowaniu jednej kopii serwisu należy przyjrzeć się organizacji treści na naszej stronie. Jeżeli używamy (jak np. w sklepie internetowym) sortowania lub filtrowania zawartości zalecane jest stosowanie tagów canonical do wskazania podstawowej (kanonicznej) wersji danego adresu url i dostępnej pod nim zawartości:
<link rel=”canonical” href=”adres-url” />.
Zalecane jest też ograniczenie do minimum lub wyeliminowanie podstron pozbawionych treści lub publikujących treść generowaną automatycznie. Jeżeli w optymalizowanym serwisie nie można ich ograniczyć z powodu np. ograniczeń CMSa można dla takich stron zastosować tag
<meta name=”robots” content=”noindex, follow” />
umieszczony w sekcji <head> dokumentu HTML. Taka reguła zapobiegnie indeksowaniu danego adresu, ale umożliwi przejście robota wyszukiwarki dalej. Do blokowania podstron nie powinniśmy stosować pliku robots.txt. Przede wszystkim jest on w wielu przypadkach nieskuteczny, poza tym blokuje on możliwość przechodzenia robota i mocy linków w głąb serwisu z blokowanej podstrony. Dodatkowo jego nieumiejętne stosowanie może utrudnić robotom Google prawidłowe renderowanie i indeksowanie serwisu (np. w przypadku blokowania katalogów grafik lub skryptów).
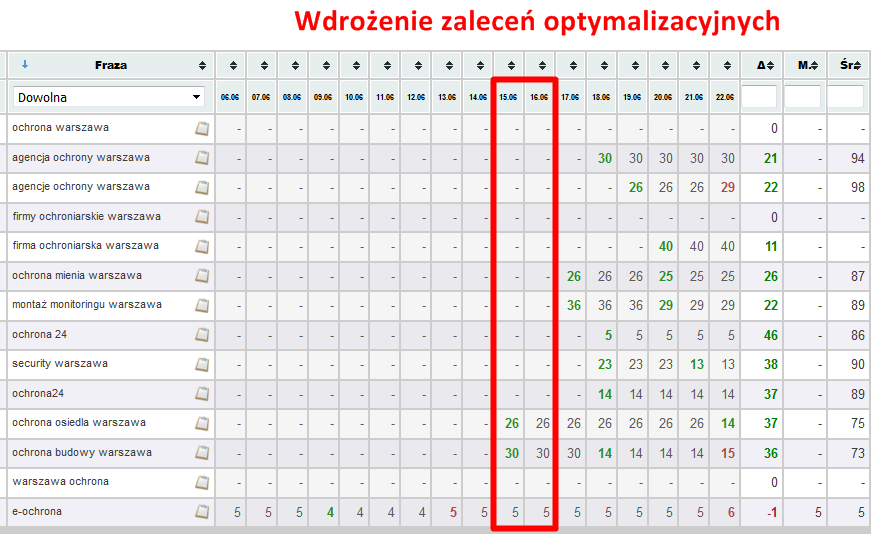
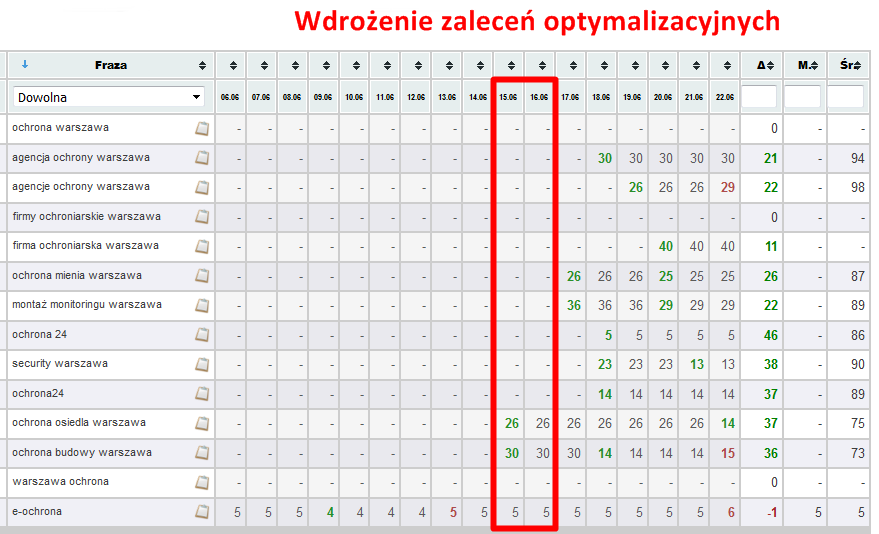
Dodanie unikalnej treści jest jednym z zaleceń optymalizacyjnych. Oryginalne teksty na stronie wpływają na umocnienie pozycji w SERP.
Stały monitoring indeksowanych podstron i dbałość o jakość publikowanych na nich treści jest szczególnie istotna w aspekcie ciągłych aktualizacji algorytmów wyszukiwarki. Google do analizy treści na stronie wykorzystuje algorytm o nazwie „Panda”, który analizując serwis może go ukarać w postaci nałożenia filtra na część lub cały serwis między innymi za publikowanie niskiej jakości treści (puste podstrony, podstrony z niewielkim opisem, wielokrotne publikowanie tej samej zawartości w różnej formie, publikowanie automatycznej treści itp..). Stosowanie powyższych wskazówek jest skutecznym sposobem na ochronę serwisu przed takimi konsekwencjami.
Pod koniec kwietnia 2015 roku, Google oficjalnie ogłosiło, że będzie promować w mobilnych wynikach wyszukiwania witryny zoptymalizowane pod kątem poprawnego wyświetlania na urządzeniach mobilnych. Wymusza to na właścicielach stron dostosowanie serwisów do poprawnego wyświetlana się na każdym urządzeniu, tak aby zapewnić dostępność publikowanych w serwisie materiałów dla każdego użytkownika sieci. Z pomocą przychodzi tutaj Responsive Design. Witryny, w ten sposób zaprojektowane, wyświetlają się prawidłowo praktycznie na każdym urządzeniu, dostosowując się dynamicznie do wielkości ekranu. Alternatywne rozwiązanie, które nadal jest wspierane przez wyszukiwarkę to posiadanie strony mobilnej. Jest to kopia serwisu zoptymalizowana pod kątem prawidłowego wyświetlania się na urządzeniach mobilnych, często pozbawiona funkcjonalności strony macierzystej. Ponieważ jest ona kopią należy zadbać o jej prawidłowe otagowanie znacznikami rel=”alternate” oraz rel=”canonical” dla wskazania wyszukiwarce podstawowej i alternatywnej (czyli mobilnej) zawartości.
Wraz z rosnącym odsetkiem użytkowników stron mobilnych na znaczeniu zyskuje także szybkość wczytywania się podstron. Google na swoich stronach dla developerów i webmasterów udostępnia narzędzia, dzięki którym możemy przetestować witrynę pod kątem dostosowania do wyświetlania na urządzeniach mobilnych oraz ocenić jej szybkość wczytywania na różnych typach urządzeń końcowych. Poza samą oceną uzyskujemy cenne wskazówki jakie elementy należy zoptymalizować, aby podnieść ten wskaźnik.
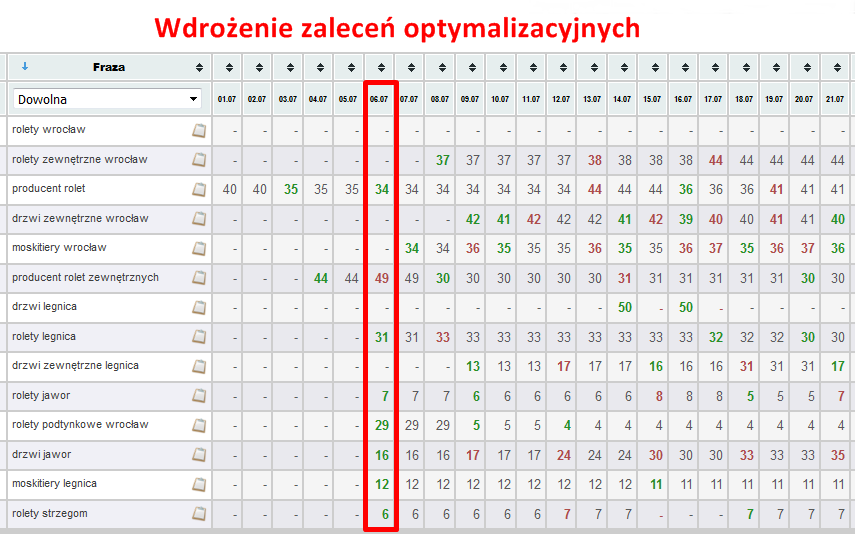
Wdrożenie wszystkich zaleceń optymalizacyjnych to połowa sukcesu w osiągnięciu zadowalających efektów z pozycjonowania.
Należy pamiętać że wyszukiwarki stale ewoluują. To, co jest istotne dla nich dziś, może być całkowicie ignorowane w niedalekiej przyszłości. Co roku jesteśmy informowani (lub nie) o kilkudziesięciu zmianach w algorytmach, jakie są stosowane przez wyszukiwarkę Google w procesie analizy stron www. Dlatego optymalizację serwisu należy traktować jako proces stały.
Więcej możesz dowiedzieć się z naszych webinarów.




